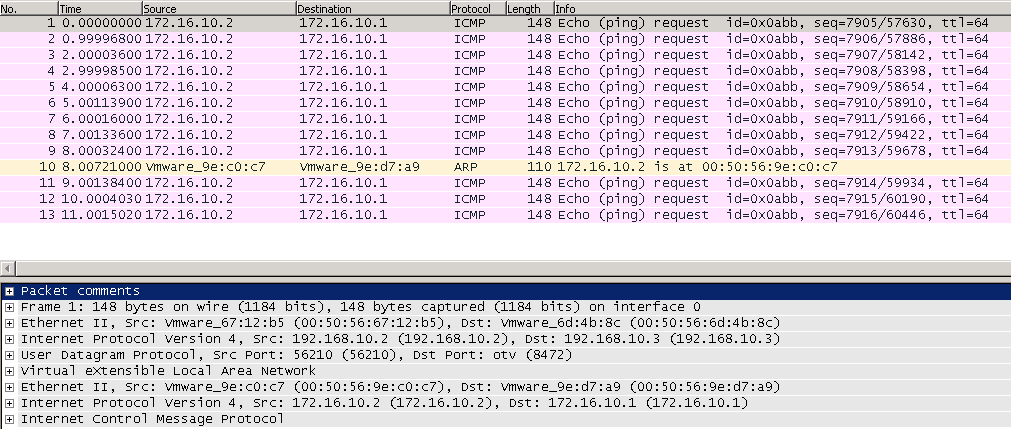
VMware NSX-T DataCenter ships with native L2 bridging capability. If you have been running NSX for vSphere and have requirements for L2 Bridging you would be familiar with the software based L2 bridging capability which is part of the functionality of the Distributed Router.
L2 bridging has a few use-cases within the datacenter and its not uncommon to see L2 bridging being configured to allow applications that reside on overlay logical switches direct layer 2 access to machines that reside outside the logical space or to physical machines residing in a VLAN
With NSX for vSphere, this feature is provided by the Distributed router. The vSphere host that runs the Distributed router control-VM acts as the bridge instance and performs the bridging function.
In NSX-T DataCenter there are now 2 ways to bridge Overlay-VLAN networks,
* L2 bridging with ESXi host transport nodes
* L2 bridging with NSX Edge transport nodes
In this article, we will look at configuring L2 bridging using ESXi host transport nodes.
To configure an ESXi host as a bridge host we first need to create a bridge cluster. The hosts in the bridge cluster need to belong to an overlay transport zone
Creating the ESXi Bridge cluster
Under Fabric –> Nodes –> ESXi Bridge Clusters. Click Add and select the hosts that will act as a bridge cluster.
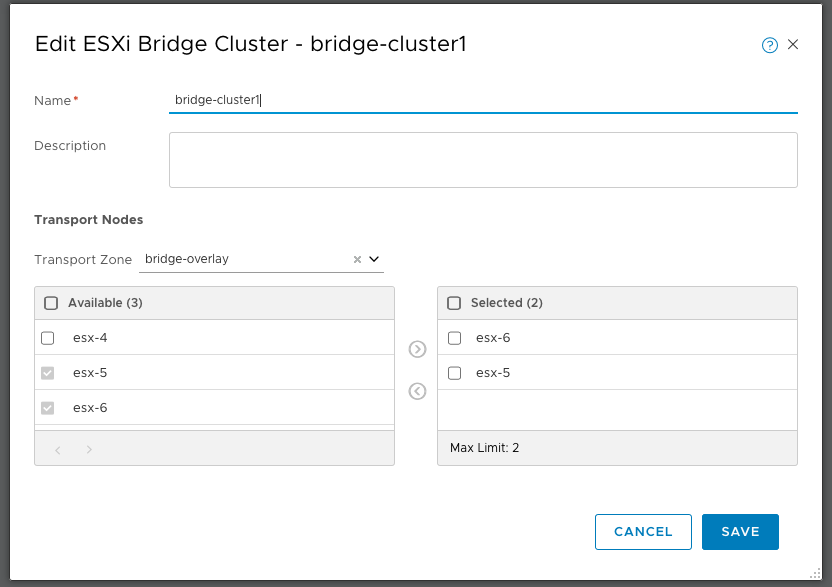
The next step is to attach this bridge cluster to the logical switch to which we want to bridge traffic. Here we specify the VLAN to bridge and turn on HA if required
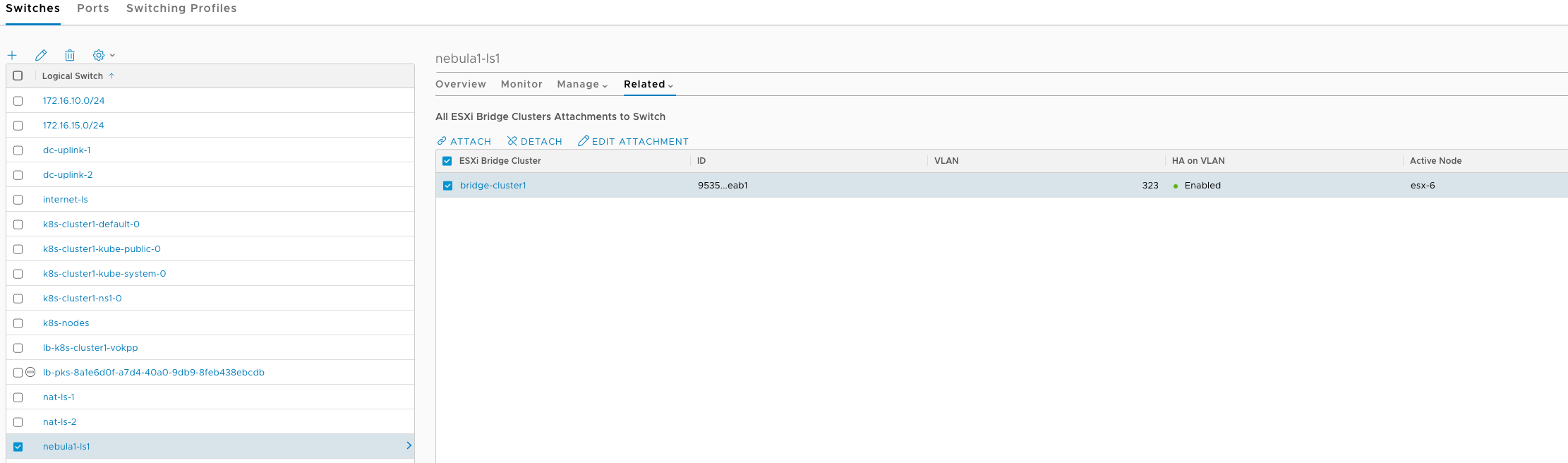
And that’s it, we should now have L2 bridge created between the overlay logical switch and the VLAN L2 segment. To validate this further we can login via SSH to the active bridge ESXi host and run the below commands,
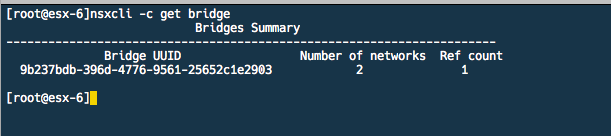
The “nsxcli -c get bridge” command will list the bridge ID and list the number of networks on this bridge instance
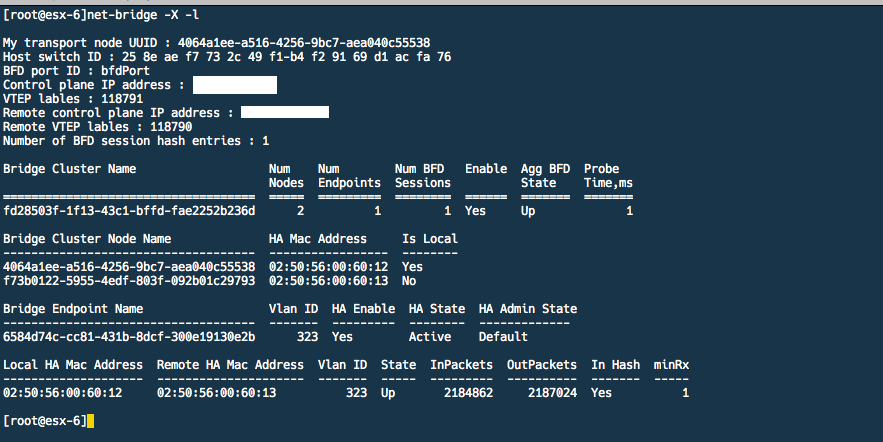
We can also run “net-bridge -X -l” which will list further information about the configured bridge. In this case, we can validate if BFD is up, state of the bridge, the VLAN ID that is being bridged, the bridge nodes in this bridge cluster and also some stats on the number of packets ingressing/egressing this bridge instance.
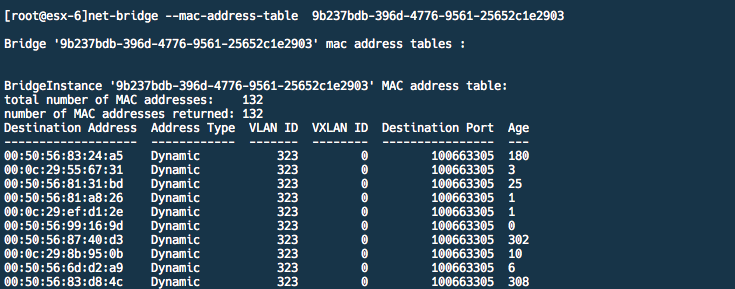
As our bridge instance state is UP we can validate if the bridge is learning MAC addresses in the VLAN segment using the “net-bridge –mac-address-table <UUID>” command
Summary
In summary, NSX-T DataCenter provides the flexibility to bridge overlay networks with VLAN networks if you have the requirement to do so.
As bridging is done in software performance is the biggest concern with this solution. To mitigate performance issues the design should look at spreading out the load across multiple bridge instances.